Olá leitores!
Hoje vamos introduzir no nosso blogue um novo tema, a codificação de caracteres.
Uma codificação de caracteres é um padrão de relacionamento
entre um conjunto de caracteres (representações de grafemas ou unidades
similares a grafemas como as que compõem um alfabeto ou silabário utilizados na
comunicação através de uma linguagem natural) com um conjunto de outra coisa,
como por exemplo números ou pulsos elétricos com o objetivo de facilitar o
armazenamento de texto em computadores e sua transmissão através de redes de
telecomunicação.
Exemplos comuns são o código Morse que codifica as letras do
alfabeto latino e os numerais como sequências de pulsos elétricos de longa e
curta duração e também o ASCII que codifica os mesmos grafemas do código Morse
além de outros símbolos através de números inteiros e da representação binária
em sete bits destes mesmos números.
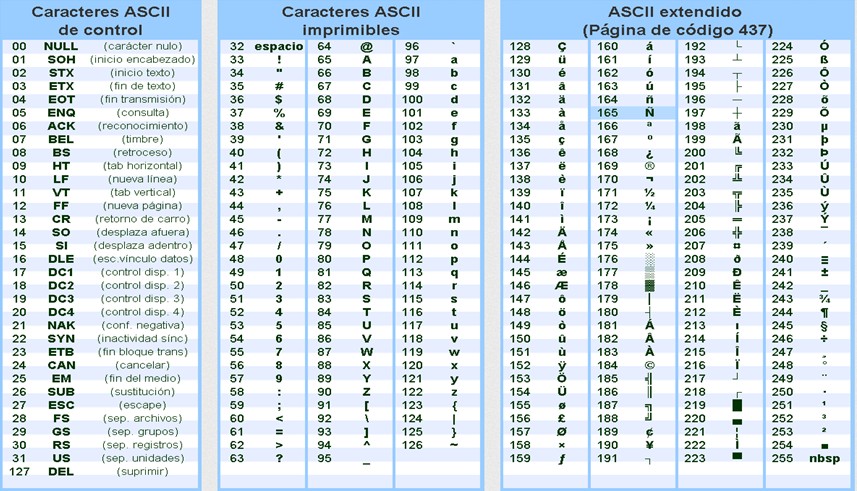
Código ASCII:
ASCII é um código binário que codifica um conjunto de 128
sinais: 95 sinais gráficos e 33 sinais de controle. Cada código binário possui
8 bits (equivalente a 1 byte), sendo 7 bits para o propósito de codificação e 1
bit de paridade (detecção de erro).
A codificação ASCII é usada para representar textos em
computadores, equipamentos de comunicação, entre outros dispositivos que
trabalham com texto.
Os sinais não-imprimíveis, conhecidos como caracteres de
controle, são amplamente utilizados em dispositivos de comunicação e afetam o
processamento do texto.
O código ASCII é muito utilizado para conversão de Código
Binário para Letras do alfabeto Maiúsculas ou minúsculas.

Unicode:
Unicode é um padrão adotado mundialmente que possibilita com
que todos os caracteres de todas as linguagens escritas utilizadas no planeta
possam ser representados em computadores. A “missão” do Unicode é apresentada
de forma clara no web site do Unicode Consortium (entidade responsável pela sua
gestão).

{kind=link}
{kind=link}
Sem comentários:
Enviar um comentário